<snip> curl -I https://www.amazon.de/dp/3446443487 HTTP/2 405 server: Server content-type: text/html;charset=UTF-8 </snip>
Handling 403 and 405 Status Codes
Issue 219 explains that the naive link checks based upon a http HEAD request sometimes fail, e.g. for links to amazon.com:
For example: (`curl -I performs a HEAD request)
This is clearly a false negative, as the URL itself is correct and the page exists.
Proposed Approach
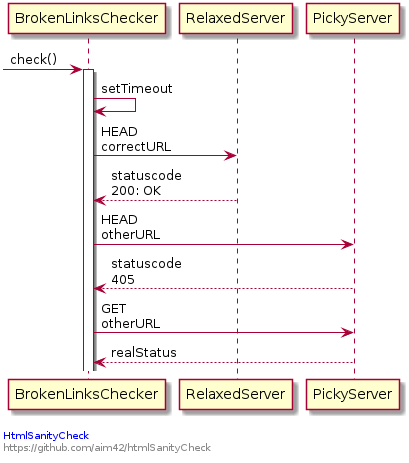
Reason for this "double check" is to keep the transmitted data volume low (and performance higher).
The general behavior we implement shall be the following `
if (responseCode in successCodes) then return
else {
// try GET
connection.setRequestMethod("GET")
int finalResponseCode = connection.getResponseCode()
switch (realResponseCode) {
case warningCodes: println "real warning $responseCode"; break
case errorCodes: println "real error $responseCode"; break
default: println "Error: Unknown or unclassified response code"
}
}Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.